Crypto Investing in 2022
One of my principles as an investor is DYOR, or “Do your own research.” The markets are teeming with misinformation, peddlers, “pump n’ dump”ers, and… those who are subscribed to Wall Street Bets.
As the popularity, or should I say, hype of cryptocurrency as a form of investment increases, so does the risk of newbie investors following the pack without doing their due diligence on projects. It is best practice to “know what you’re investing in.” So, often, wise investors will read the whitepaper set out by the coin or project in order to understand the logic behind the project and determine whether it has actual viability or if it’s just a rug pull (See Squid Game Is Memecoin Warning With Wipeout After 230,000% Gain) or a project that works better in concept (See The LUNA and UST Crash Explained in 5 Charts).
The Need for non-English Cryptocurrency Whitepapers
However, the majority of blockchain projects are in English, and nearly all whitepapers are written in English – despite the number of global crypto users rising to over 300 million worldwide in 2021. The better access crypto users have of the projects and whitepapers in their language, the easier it is for them to make informed investment decisions.
A Goal of Training an English to Chinese Cryptocurrency Machine Translation Engine
With the goal of promoting a return to traditional investment practices of doing due diligence, I and a team of four set out to train a neural machine translation engine on translating cryptocurrency whitepapers. We began with an English to Chinese language pair. While the Chinese government has tightened regulations on cryptocurrency, there is no doubt that China will be a big player in the crypto/blockchain industry one day; there is speculation that China is also developing its own digital currency.
Step 0: Determining Pilot Objectives
To our knowledge, nothing of this sort has ever been done. We were going in cold.
The best thing to do when you don’t know what to do is determine where you want to end up and backtrack the steps to draw a roadmap.
We laid out three goals for the MT engine.
| Pricing Goals | PEMT 30% cheaper than human translation |
| Timing Goals | PEMT 40% faster than human translation |
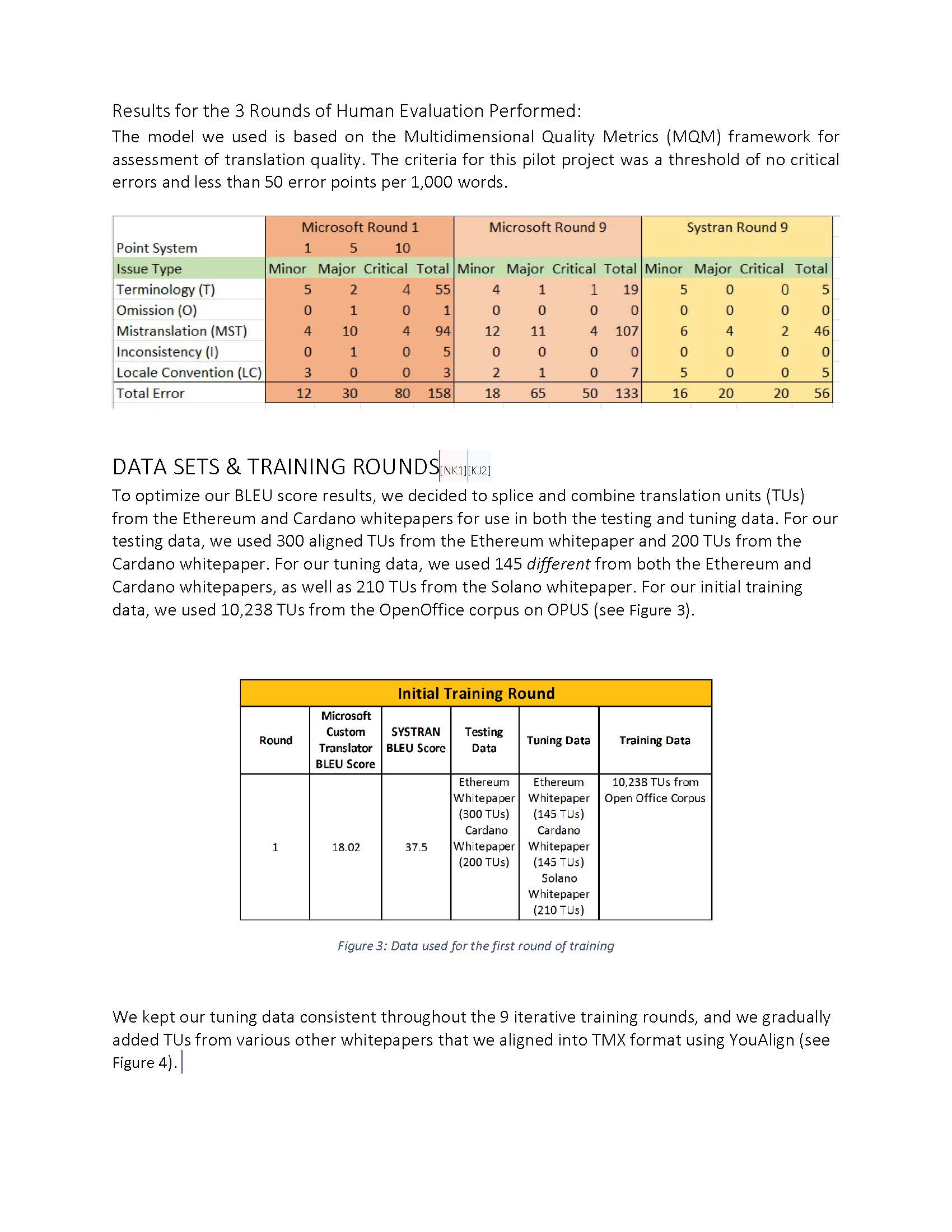
| Quality Goals | PEMT has no critical errors and errors in other categories are below 50 points per 1,000 words based on a modification of the MQM quality model. |
Step 1: Gathering Data
The first step in training a neural machine translation engine is gathering the necessary data to feed the engine. This proved to be slightly difficult. For starters:
- There are no high quality (if any at all) publicly available corpuses focused on cryptocurrency or blockchain
- Documents were scattered across project sites, pdfs, and tmx files
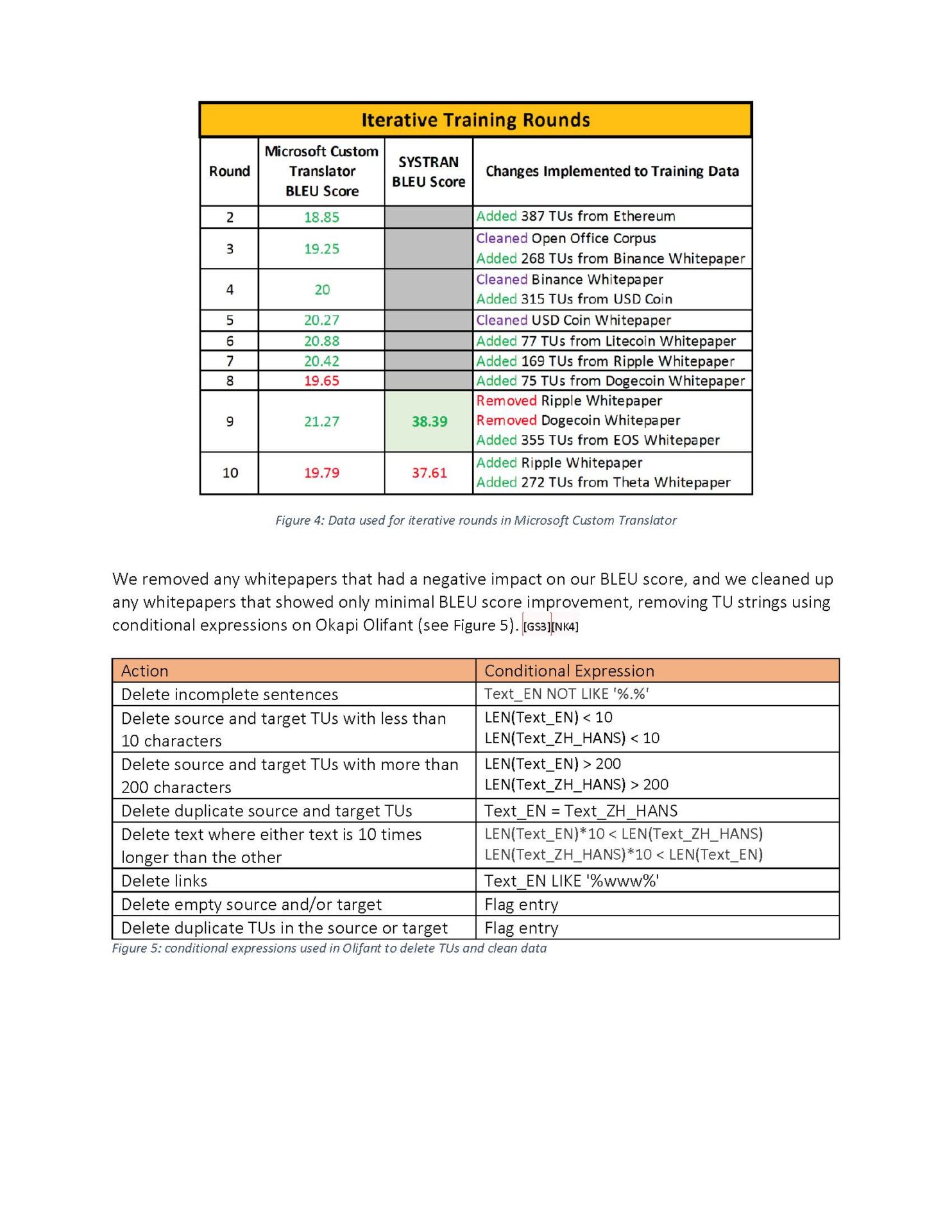
We had to manually convert, align, and clean whitepapers found online to come up with the training, testing, and tuning data for the MT training.
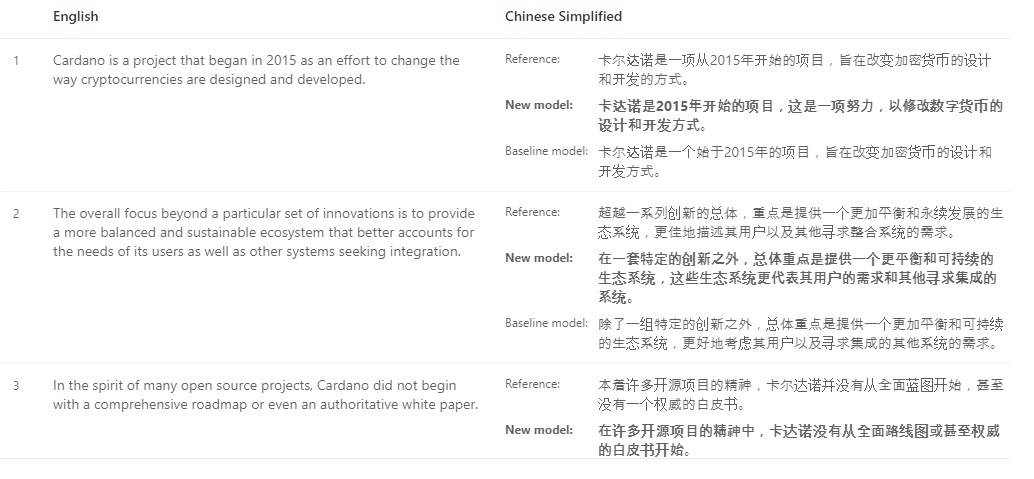
Step 2: Train MT engine and Evaluate (and repeat…)

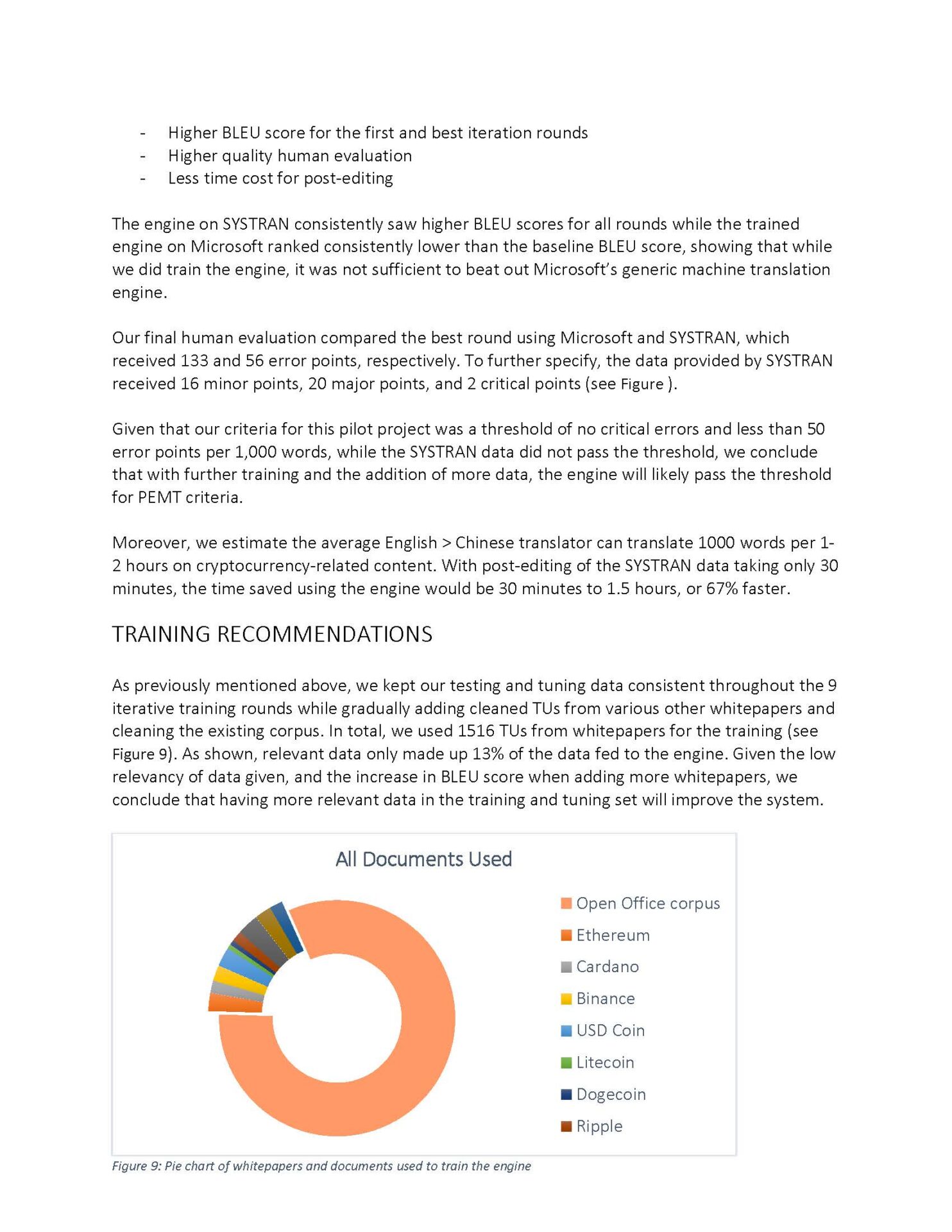
This is our workflow for the project.
While actually training the engine isn’t too difficult (a mere matter of uploading and choosing the correct files and waiting for the engine to train itself), it’s deciding on what elements to change for the next iteration in order to increase the BLEU score (an algorithm for evaluating the quality of machine-translated text) that proved difficult.
Should I add more whitepapers to the training data? Should I change the tuning data? Which translation units (individual translatable segments) should I delete from the data to keep it more relevant? How can I balance high quality data and my sanity?
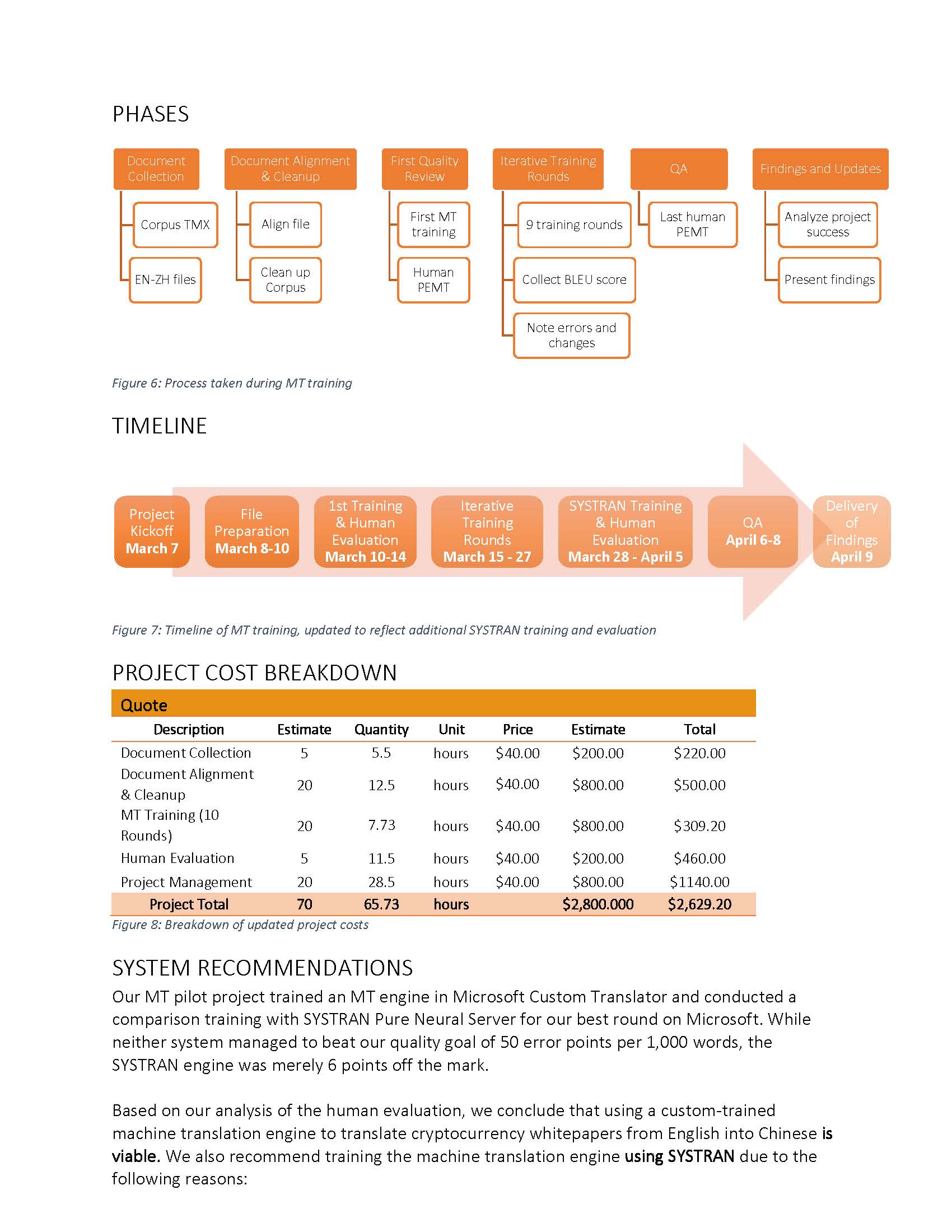
I suggested we keep track of data cleaning filters like below:
| Action | Conditional Expression |
|---|---|
| Delete incomplete sentences | Text_EN NOT LIKE ‘%.%’ |
| Delete source and target TUs with less than 10 characters | LEN(Text_EN) < 10 LEN(Text_ZH_HANS) < 10 |
| Delete source and target TUs with more than 200 characters | LEN(Text_EN) > 200 LEN(Text_ZH_HANS) > 200 |
| Delete duplicate source and target TUs | Text_EN = Text_ZH_HANS |
| Delete text where either text is 10 times longer than the other | LEN(Text_EN)*10 < LEN(Text_ZH_HANS) LEN(Text_ZH_HANS)*10 < LEN(Text_EN) |
| Delete links | Text_EN LIKE ‘%www%’ |
| Delete empty source and/or target | Flag entry |
| Delete duplicate TUs in the source or target | Flag entry |
Evaluation of the MT is also crucial to maintaining quality. It’s not enough to rely on a BLEU score and think your translation is good. Getting a human evaluator to actually look at the translation is crucial to picking out the blind spots in the engine and deciding on what changes to make in the following iterations.
Our team prepared our lessons learned in a video presentation below.
We also created a proposal for the pilot project that you can view here.